GO-TO-GO Why Hima (‘free time’) is Bad and Ushiro (‘back’) is Scary?
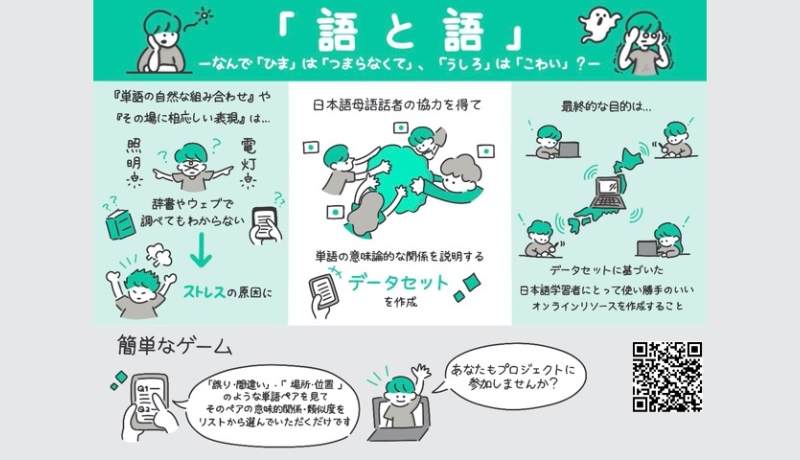
A crowdsourcing project collecting information on semantic relations and similarity of word associations.
https://www.zooniverse.org/projects/mariatelegina/go-to-go https://www.facebook.com/kotoba.no.kankei
Abstract
In the culturally and linguistically diverse community our world has been turning into, we have to learn, teach, write, speak, and work in a variety of languages. That is why the struggle and stress of not being able to find the “right word” or “naturally sounding combination of words” when communicating in a foreign language are so clear and familiar to most of us now.
While many tools and sources for written and spoken speech reference and learning for Indo-European languages such as English, French or Spanish are easily accessible, Japanese remains underrepresented in this domain. Even considering the recent trends towards globalization and internationalization, there is a lack of user-friendly tools and resources for learners, who want to read, communicate, learn, and work in Japanese.
Over the last several decades, linguistics researchers have developed a large number of data-driven resources based on written texts, spoken language, and word associations. However, none of these resources contain extra-linguistic culture-specific information, which can be utilized for natural language understanding and for language teaching and learning. Moreover, the majority of such resources based on Japanese data are specialists oriented.
This project aims to collect a dataset containing semantic relations (e.g., synonymous, antonymous, culture-specific) and similarity information provided by Japanese native speaking volunteers. The future goal of the project is to create a user-friendly resource for Japanese learners based on the collected dataset.